
Tutti noi oggi usiamo Google, spesso anche con la ricerca vocale, per cercare informazioni e soprattutto ottenere risposte ai nostri dubbi o curiosità.
Ma in che modo Google produce quei risultati? Come arriva a definire quale pagina rispetto a un’altra risponde meglio alle richieste di un utente?
Se vuoi iniziare a capire come un motore di ricerca determina i risultati che mostra a una persona in seguito a una sua ricerca, devi cercare di capire come funziona tecnicamente un motore di ricerca.
Indice
Come funziona la ricerca di Google: scansione, indicizzazione e posizionamento di un sito
Quando inserisci dei termini nella casella di ricerca del motore, termini che tecnicamente si chiamano query, il motore passa in rassegna il suo catalogo di pagine alla ricerca di quelle più adatte.

Motori differenti hanno criteri differenti per scegliere le pagine, ma l’idea di base è quella di assicurarsi che le pagine migliori e più importanti arrivino prima nei risultati di ricerca. Così facendo le persone continueranno a usare sempre di più quello strumento.
Nello specifico, tutto il processo di fornitura dei risultati di ricerca viene gestito da software che si occupano di 3 fasi: scansione, indicizzazione e posizionamento.
La scansione (crawling)
Il crawling, o scansione, consiste nella consultazione del maggior numero di informazioni presenti sul web, tramite un programma automatico chiamato spider (o robot, o bot, o crawler) e la successiva copia in un database dei contenuti trovati.
Il crawler del motore di ricerca è principalmente interessato a certi tipi di informazioni sulla pagina, in particolare l’URL, il testo e i link sulla pagina. Tuttavia anche le immagini e altri tipi di media, come i pdf, vengono passati in rassegna dalla maggior parte dei motori di ricerca.
Facilitare il lavoro del crawler è uno dei compiti principali di chi si occupa di ottimizzazione di un sito per i motori di ricerca.
Ogni tanto lo spider ritorna su un sito già analizzato per aggiornare i propri dati. La frequenza di questi passaggi è variabile, così come può variare il numero di pagine di un sito che viene indicizzato, numero chiamato profondità della scansione.
Se sei curioso di sapere quali pagine Google ha rilevato (e quali no), puoi accedere al tuo account Google Search Console e poi cliccare la voce Pagine (sotto Indice, nella colonna sinistra).
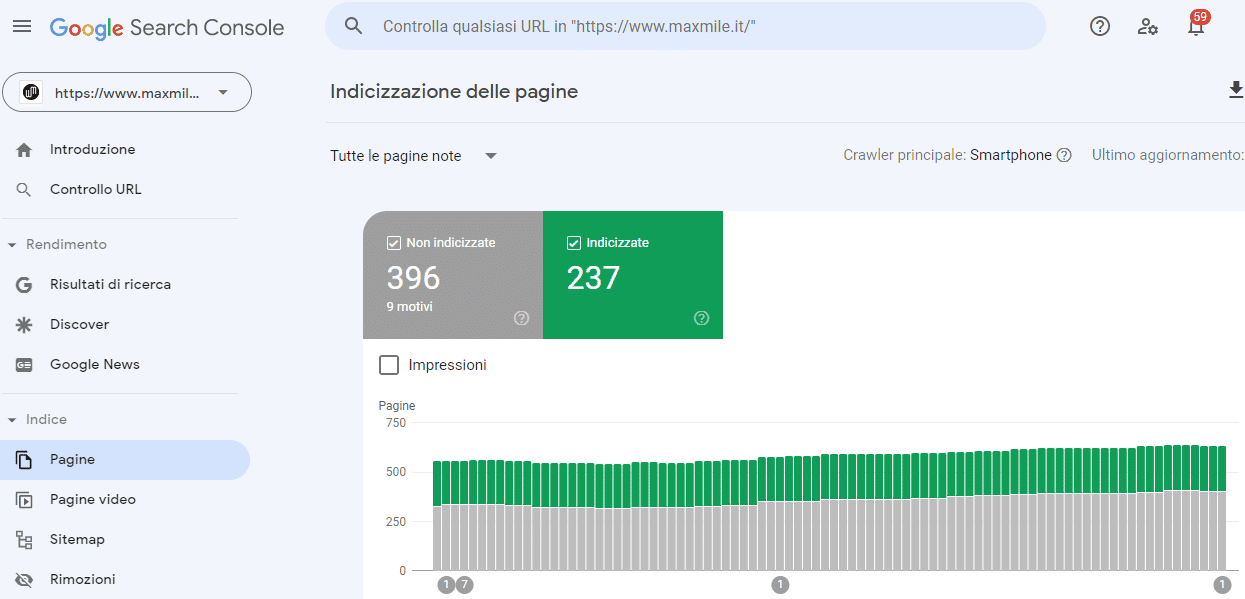
L’indicizzazione (indexing)
Eseguita la scansione del sito, il motore passa alla fase di indexing. Le pagine individuate vengono elaborate per estrarne le informazioni rilevanti al fine di stabilirne la posizione.
In altre parole, i dati raccolti dal crawler vengono analizzati da un altro software, detto indicizzatore, che li elabora secondo certi parametri, come il titolo della pagina, i contenuti, la lingua, la frequenza di aggiornamento, ecc.
Il software salva tutta questa elaborazione in un catalogo, tecnicamente un gigantesco database, chiamato appunto indice.

Un aspetto importante della fase di indicizzazione è che il software crea il “vocabolario” dei termini presenti nella pagina.
Queste prime operazioni di calcolo si definiscono “indipendenti dalla ricerca” (query-independent) poiché vengono eseguite a prescindere dalla ricerca eseguita dell’utente.
L’indicizzazione può avvenire a intervalli prestabiliti o in tempo reale.
Il posizionamento (ranking o serving)
Una volta che le informazioni sono state raccolte e catalogate, resta l’ultima fase del processo di un motore di ricerca: la fornitura delle informazioni richieste dai visitatori, il serving.
Sulla base delle parole digitate nella casella di ricerca, il motore interroga l’indice e restituisce i suoi migliori risultati in una pagina, chiamata tecnicamente SERP (Search Engine Result Position).
Dunque, la SERP è la pagina dei risultati di un motore di ricerca.
Mettere tutto insieme
Per poter indicizzare, cioè inserire nell’indice del suo database le risorse di un sito web, Google deve prima eseguire una scansione di queste risorse.
La scansione viene effettuata attraverso un crawler, cioè un software chiamato bot, Googlebot nel caso di Google. Il bot ha il compito di recuperare tutti gli URL di un sito.
Per URL si intendono non solo le pagine web di un sito, ma anche le immagini, i documenti pdf e qualsiasi documento raggiungibile via web.
Per eseguire questa scansione, il bot deve “arrivare” su un URL del sito e può giungerci:
- Se hai fatto conoscere a Google l’esistenza delle tue pagine, tipicamente tramite l’invio di una mappa del sito in formato XML su Search Console.
- Se un sito diverso dal tuo ha un link verso il tuo sito.
Atterrato su uno dei tuoi URL, Googlebot inizia la scansione passando di URL in URL grazie alla rete di link presenti nel sito.
Il crawl budget
Nel 2017 Google ha reso noto attraverso una comunicazione ufficiale, l’esistenza del concetto di crawl budget, definendolo come “il numero di URL che Googlebot può e vuole scansionare”.
Ciò significa che il bot di Google ha un budget di tempo entro il quale eseguire la sua scansione per un sito.
Ora, mentre per siti con un basso numero di contenuti ha poco senso preoccuparsi di questo parametro, per siti con un numero elevato di risorse come portali di news o e-commerce, siccome questo tempo è limitato, bisogna “indirizzare” il crawler verso le risorse più importanti del sito.
Come ottimizzare il crawl budget di Google
Come puoi “richiamare l’attenzione” del crawler di Google in modo che concentri la sua scansione sulle risorse più importanti del tuo sito?

Ecco 7 tecniche che puoi utilizzare per indirizzare correttamente il Googlebot.
- Evita la scansione di contenuti inutili, per esempio tutti gli URL del pannello di amministrazione dei contenuti, le cartelle private, i file pdf, le pagine di cookie e privacy policy, le pagine di servizio di un e-commerce (es. carrello)
- Imposta una corretta struttura del sito gerarchizzando i contenuti attraverso i menu di navigazione e i link presenti nelle pagine del sito (link interni)
- Verifica la presenza degli status code diversi da 200 e correggerli
- Utilizza i canonical per pagine che hanno lo stesso contenuto e i link no follow per indicare al bot di non seguire quel link, per esempio i link verso cookie e privacy policy
- Piazza il sito su un server che fornisce le pagine molto velocemente, così che il crawler perda meno tempo ad aspettare il contenuto delle risorse
- Aggiorna periodicamente i tuoi contenuti, in modo da “invogliare” il crawler a ritornare a scansionare il tuo sito. Nota che il tempo stabilito dal crawler non è fisso, ma varia a seconda dei risultati delle scansioni. Se trova contenuti periodicamente nuovi, tornerà più spesso e aumenterà il suo crawl budget.
- Rimuovi i contenuti inutili per indirizzare il crawler su quelli più utili. Controlla su Google Analytics le pagine meno visitate ed esegui un’analisi per capire se rivederle o rimuoverle.
Se vuoi approfondire l’argomento, Google ha creato una pagina specifica dedicata agli sviluppatori, per la corretta gestione del budget di scansione.
Conclusioni
Sebbene non si applichi a tutte le tipologie di siti web, l’ottimizzazione del tempo che il crawler mette a disposizione per scansionare il tuo sito è un’attività molto importante per permettere al bot di capire quali sono i contenuti da valorizzare nelle sue pagine dei risultati (o SERP).
Scopri come la SEO può portare nuovi livelli di visibilità alla tua azienda e attrarre più clienti visitando la nostra pagina dedicata al servizio di posizionamento sui motori di ricerca.